Build real enterprise search in your Joomla site. Don’t limit your search to just page content or a Google or Yahoo! Search box. Deliver full search of up to 500,000 documents with the Esearch Joomla component powered by TNR’s SolrHQ system running Solr
Side-by-side comparison
| Enhanced Joomla! Search | Normal Joomla! Search |
| {loadposition esearch-module-example} | {loadposition search-module-example} |
Abstract:
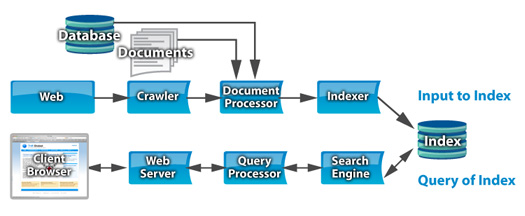
TnR Global Enterprise Search Component for Joomla driven by IBM Yahoo! OmniFind Edition is a standard Joomla component that can be installed into the Joomla open source content management system. The component (and a matching search module) provide the Joomla site with direct access to an OmniFind search system. The Joomla administrator can define the look of the search box and the search results using a standard CSS file and a Smarty template. The OmniFind enterprise search can be placed on any server the Joomla system can reach, allowing it to be behind a corporate firewall.
The component is designed to provide enterprise search for your Intranet or Extranet, as well as corporate information to clients on your public web site. All content collections that you want to make available can now be published with the full power of IBM enterprise search.
Full featured Joomla Component and Module
The component (and a matching search module) provide the Joomla site with direct access to one or more OmniFind search systems. OmniFind can run on the same server as the Joomla system or on an enterprise search server behind a firewall.
Match Site look with Search/results Template
The search box and the results look are controlled using a Smarty template and a standard CSS file. The Joomla
administrator has full control of the appearance of the search results page and can add additional controls and filtering to OmniFind search.
Enterprise Search connector interface
Connectors enable the TnR Global ESearch component to connect to many different types of search engines. The Search Connector is a single file that tells the Esearch Component how to access the installed search engine. In addition to providing functionality to search, the connector also defines its human-readable name and any additional parameters it needs from the user. Creating a Search Connector should be done by an experienced php programmer.
The IBM Yahoo! Edition OmniFind Search Connector is provided with the component by default.
The component is available as a free download.