
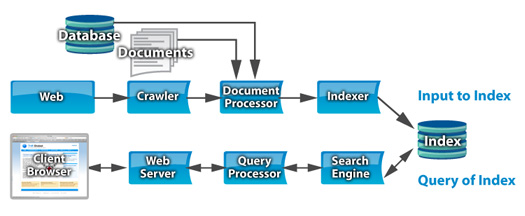
A Enterprise Search engine has two sections, a front end and a back end. They both operate in conjunction with the search index. The index is build statically for search speed, and is updated periodically. This is unlike a database where the indexes are built and keep current as any data in the database changes.
Back End:
The back end are the functions that create and update the index
Crawler – This module reads and collects web pages and follows the links between them, starting with a list of initial URLs.
Document Processor – This module processes web pages feed from the crawler, as well as databases from a ‘database connector’ and directories of files. It pulls the meaningful text from the documents, no matter the type, and adds whatever meaningful ‘meta-data’ it can determine, such as title or authors.
Indexer – This module does the brute force work of creating and maintaining the index from the documents fed from the document processor.
Front End:
The Front end are the functions that respond to a user’s request for search.
Web server – The user’s browser fetches a web page from the web server with a search form and sends responses with the user’s query back to the web server.
Query processor – The web server sends a request with the user’s query to the query processor, which properly formats the request and sends it to one (or more) search modules, collects the results and sends them to the web server for final formating.
Search Engine – This does the heavy lifting of searching for the query within the index created by the back end.